Ok, maybe not exactly four thousand, but close enough.
During my free time, I’m developing Omnisearch. Behind that so original name lies a search plugin for the note-taking app Obsidian. In short, Omnisearch uses an industry standard algorithm to return “smart” results: when you type in a query, each note is given a weight, and the notes with the higher weights are sorted on top.
One of the most important features I wanted to add was PDF indexing. Now, I know that PDFs are a can of worms, so I wasn’t going to start working on it without making sure that a) I could do it and b) it wouldn’t eat my evenings for 6 months.
PDF.js, round one
Since Obsidian is an Electron app, PDF.js1 was the obvious choice - even more obvious that I quickly found out Obsidian has it bundled. I think it took me less than an hour to wrap the feature, and ship a new version of Omnisearch. That was easy, I was wondering why it wasn’t even a default feature.
Except that if you have more than two dozens PDFs, Obsidian crashes. A hard, unrecoverable, Electron crash. Whoops, let’s rollback and try again.
PDF.js, round two
So, I tried again, but this time I added PDF.js as an Omnisearch dependency. I wasn’t too happy to do it because it made the main.js file jump from 70KB to 1.34MB. See, PDF.js is great, but it’s not really an embeddable library that plays well with tree-shaking. It’s developed by Mozilla as Firefox’s PDF viewer, so not really something you’d use to just parse PDFs. But, hey, it works. it added some freezes, but that was an encouraging start. Until crashes appeared again.
It didn’t matter if I was parsing them fast or slow, the end result was a crash. The more files, the more likely Obsidian was going to crash. And during all those tests, there was a small issue that was bugging me, and that I wasn’t able to fix. Each time PDF.js was starting, there was this message in the console:
Warning: Setting up fake worker 2
I tried everything, I never managed to make it go away. Is it related to the crashes? Maybe. Anyway, back to square one.
Let’s sprinkle a bit of Rust (and change the bundler)
Luckily I have some experience in the language Rust, and while I hadn’t done it yet, I knew it’s a language that you can (theoretically) easily compile to WebAssembly (wasm). Wasm is a way to take a fast, lower-level language, and make it run in a webapp, alongside the easier - but relatively slower - JavaScript.
Thanks to an excellent example project3, I quickly made a prototype with a fork of pdf-extract4, though it required me to change my bundler from esbuild to Rollup. I did try to make wasm work with esbuild, but it was seamless with Rollup, so I didn’t push it.
Extracting PDFs’ texts with wasm was working, but it was much slower than I expected, and worse, Obsidian was completely freezing during indexing. Indeed, wasm execution was taking 100% of the main thread, which is usually not good for the user experience.
Use ALL the cores!
Now that I’ve added wasm, let’s delegate the heavy work to web workers. Those little fellas are a way to use multi-threading in JavaScript. I mean real multi-threading, not Promises. Give them a long-running, UI-blocking task - like, say, reading PDFs - and they’ll work in the background, then send you the result once they’re done.
Phew. Does it work now? Can we index PDFs without blocking everything? Yes! Oh wait, no.

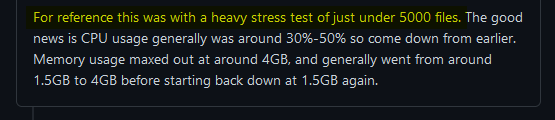
I mean, yeah, 5000 PDFs. I wasn’t really surprised that Obsidian couldn’t keep up, but I had to mitigate it. A plugin causing a hard crash is inexcusable, so it had to be fixed before going out of beta.
Honestly at that point, I was getting kinda exhausted. What was supposed to be a one-hour job had already become a 15-evenings slog. It was working on my machine (as always) with a dozen PDFs, but the more files, the more Obsidian was struggling, before completely giving up. And the crashes were not unlike the ones I experienced with PDF.js… It took me two days (and a lot of sloooowwwww reloads) to find the actual issue.
/* abridged code */
class PDFManager {
public async getPdfText(file: TFile) {
const data = new Uint8Array(await app.vault.readBinary(file)
const worker = new PDFWorker({ name: 'PDF Text Extractor' })
worker.postMessage({ data, name: file.basename })
worker.onmessage = (evt: any) => {
/* index the text */
}See what’s wrong? I was spawning a new worker for every PDF, and Electron (the engine under Obsidian) doesn’t like that. Obvious in hindsight, but hard to see when getting tired of working every evening on a feature you’re not really going to use yourself. Those workers are never cleaned, they hang out in memory (even when doing nothing) and inevitably end up causing slowdowns and crashes.
So I promptly fixed that with a pool of workers, and ta-da!
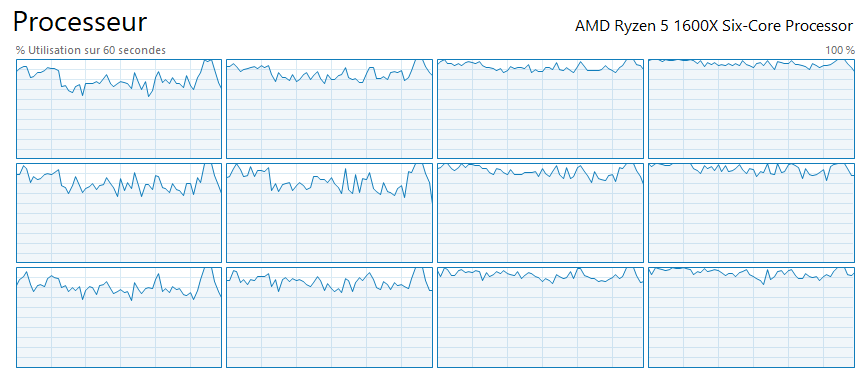
All my CPU cores happily extracting text from PDFs, in parallel, while Obsidian stays mostly unaffected. Mostly? Yep, sometimes it lags. Or freezes. For a few seconds only. Ok, maybe twenty. Sigh 😫
The never-ending optimizations
This post is already long enough, and I’m not a good writer. Sequence of tenses is already hard enough in French… Anyway.
Let’s say that, today, October 25, exactly one month after I started working on this feature, it finally appears to be silky smooth. It’s not super fast, the initial cache building takes time, but it’s smooth. I had to completely refactor Omnisearch, make small optimizations that definitely mattered at scale, and consider uses of Obsidian that are radically different than mine.
I also had to throw away the old cache implementation, after struggling with it for three days. Because I had to deliver the PDF baby, and the cache was in the way. PDFs themselves are still cached, but for now, the search index is still rebuilt at every startup. A bit inconvenient for some users, but I’ll come back to it in a few days, once I’ve spent a few evenings playing video games instead of programming.
All for this
 A single opt-in checkbox.
And I’m really, really proud of it. Not only did I learn a lot while working on this, but there’s also nothing better than a complex piece of work being completely invisible to the end-user.
A single opt-in checkbox.
And I’m really, really proud of it. Not only did I learn a lot while working on this, but there’s also nothing better than a complex piece of work being completely invisible to the end-user.
I’d also like to thank tekwizz123 and Benny, who provided incredibly useful feedback during this month of development. Four thousand thanks to both of you, and of course, to the users who take time to fill Github issues.
If you’re interested to see how the feature developped, day by day, you can read the Github issue thread5